En la etapa de recolección de datos se debe permitir abordar los datos de gran variedad de fuentes y formatos. No obstante, garantizar que todas las estructuras sean usables para el procesamiento posterior con las tecnologías disponibles es un gran reto. Para el tratamiento de datos educativos dentro del modelo de dominio específico, se propone un módulo compuesto por cuatro fases, como se puede apreciar en la siguiente figura:
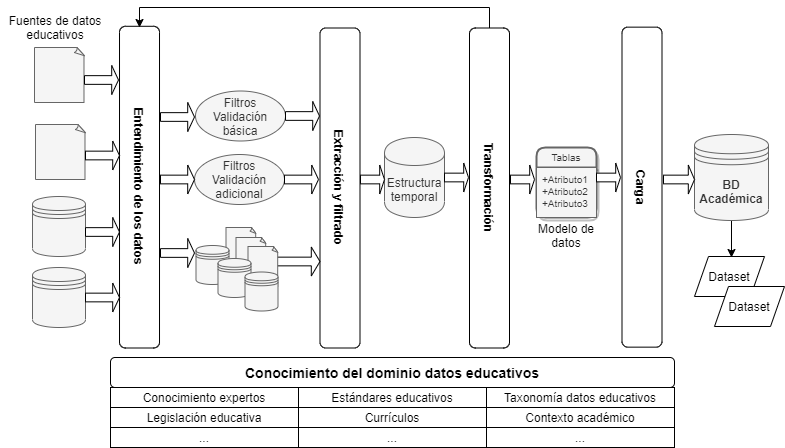
Existe una barra horizontal que es paralela e interviene en todo el proceso, se trata del conocimiento propio del dominio de datos educativos, el cual es alimentado por diferentes abstracciones tomadas del ambiente educativo, como es el conocimiento de los expertos, los estándares educativos, la taxonomía de datos educativos, la legislación educativa, los currículos, el contexto académico, los perfiles de estudiante, las políticas institucionales, entre otros. A continuación, se hace una descripción de las fases.
Fase de entendimiento de los datos: las fuentes de datos institucionales, que pueden tener diferente estructura y formato, son la entrada a esta fase. Pueden ser archivos planos, bases de datos, logs de aplicativos, entre otros. Una vez se reciben los datos e identifican las estructuras, formatos y tipos, se empieza a hacer uso del conocimiento del dominio para entender las relaciones existentes y los problemas que se deben enfrentar. En este punto, uno de los aspectos fundamentales es poder contar con la ayuda de los expertos o propietarios de los datos, porque son ellos quienes tienen a priori el conocimiento y dominio de los sistemas que están generando la información. Las salidas de esta fase son los filtros que se usarán en la siguiente etapa; además, las fuentes de datos, que no sufren ninguna transformación o preprocesamiento, pero de las cuales se hace una copia para conservar el original y luego poder hacer comparaciones (si es requerido una vez son aplicados los filtros) y para tener una trazabilidad de las alteraciones realizadas.
Fase de extracción y filtrado: está compuesta por dos actividades: filtrado de validación y extracción. En la primera se reciben los datos originales en su estructura, se examinan y detectan posibles problemas por medio de los filtros de validación básica, por ejemplo, la escala de calificaciones, el número de dígitos de un documento de identidad, entre otros. La validación también puede tener filtros compuestos, estos filtros tienen en cuenta dos o más atributos y requieren de haber extraído, desde el conocimiento del dominio, información que no necesariamente está a priori en la documentación del sistema o fuente de datos. Una vez filtrado también se hace la extracción, siendo la salida, los datos extraídos y llevados a una estructura temporal.
Fase de transformación: la entrada de esta fase es una estructura temporal con los datos filtrados, esta estructura existe para permitir validar y separar los datos ya filtrados y los que requieren revisión. En este punto, se verifica con el conocimiento del dominio, para saber si los datos que no pasaron el filtro necesitan una transformación para llegar al almacenamiento, o si por el contrario se detecta la necesidad de modificar el filtro o si finalmente se determina que el dato está errado y debe ser retirado. Esta fase es una fase de refinamiento, porque puede existir tanto transformación de los datos como transformación de los filtros, es por ello, que en el diseño se establece que desde esta fase se puede regresar a la fase de entendimiento de los datos, porque incluso los filtros pueden requerir modificación. Se puede dar también una transformación de formatos o tipos de datos. La salida de esta fase es el modelo de datos y los datos listos para ser cargados.
Fase de carga: esta es la última fase del proceso, consiste en tomar los datos que ya han sido filtrados y están limpios en la estructura temporal y llevarlos al modelo de datos para ser cargados en una base o bodega de datos académica. El conocimiento del dominio puede también influir en esta fase de carga, por ejemplo, en la selección del orden en el que tendrán que ser tomados los datos para llevarlos al almacenamiento, dependiendo de las relaciones establecidas en el modelo de datos. Finalmente, la salida de esta fase será la base de datos poblada y a partir de la cual se podrán extraer los dataset para la aplicación de las técnicas de minería de datos.
Un comentarista de WordPress
Hola, esto es un comentario.
Para empezar a moderar, editar y borrar comentarios, por favor, visita la pantalla de comentarios en el escritorio.
Los avatares de los comentaristas provienen de Gravatar.